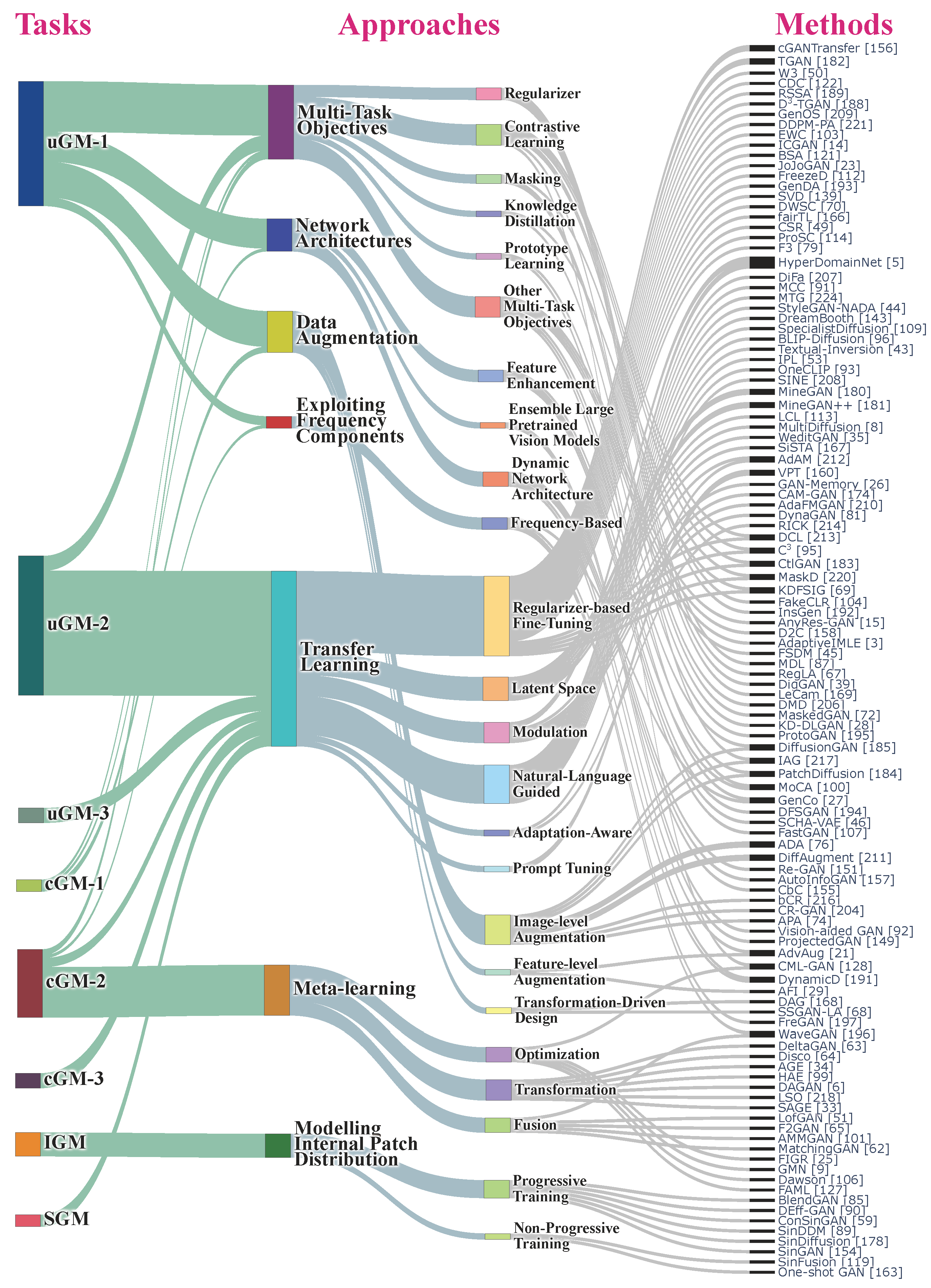
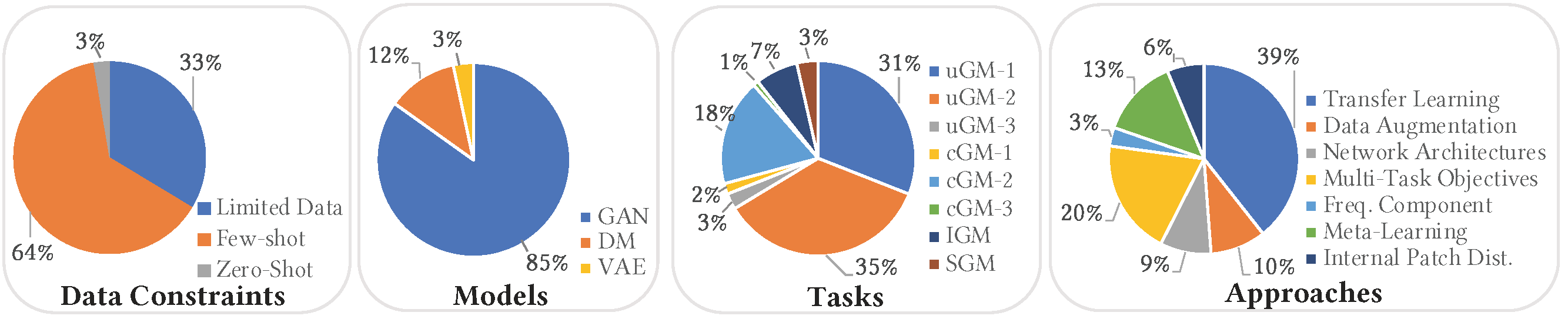
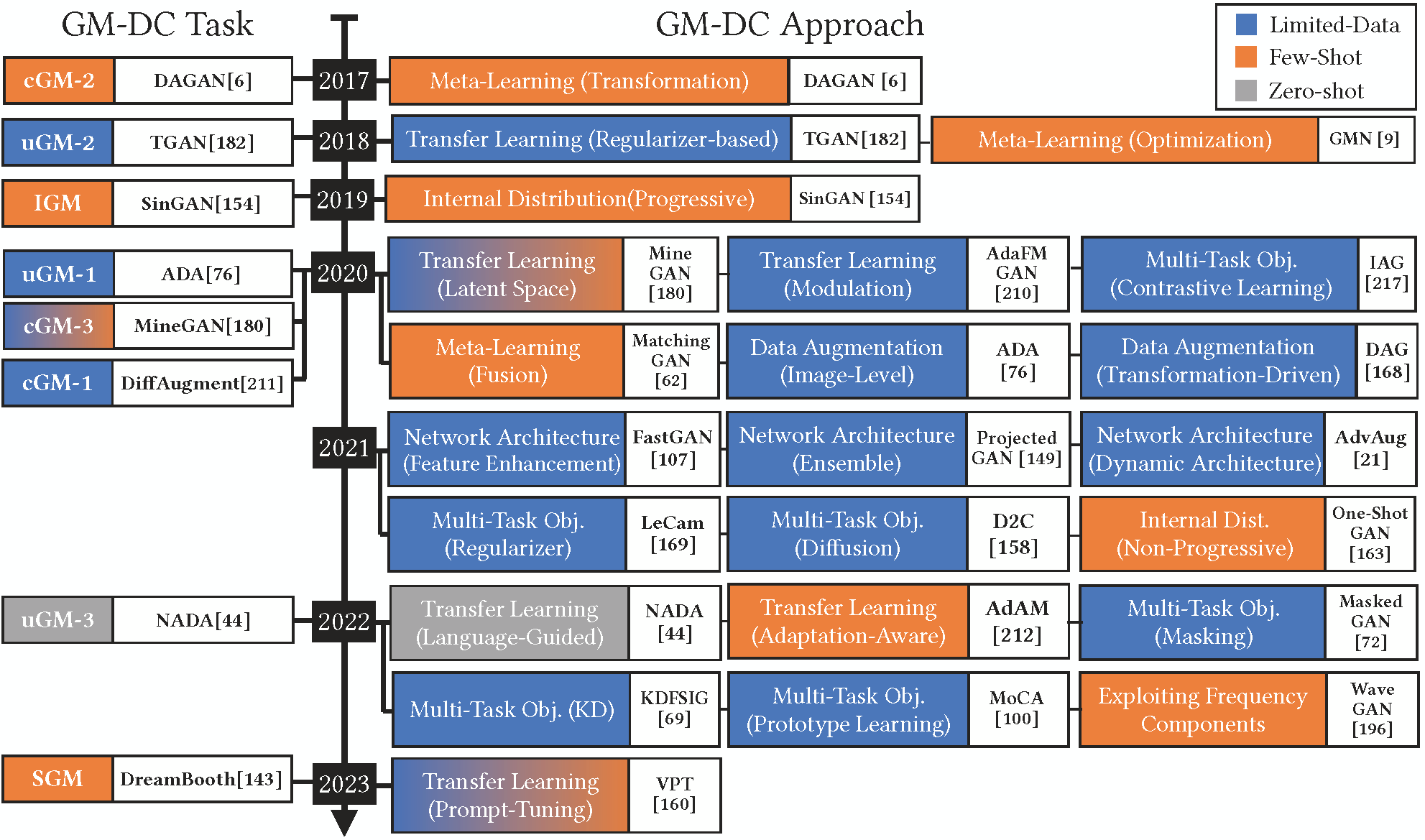
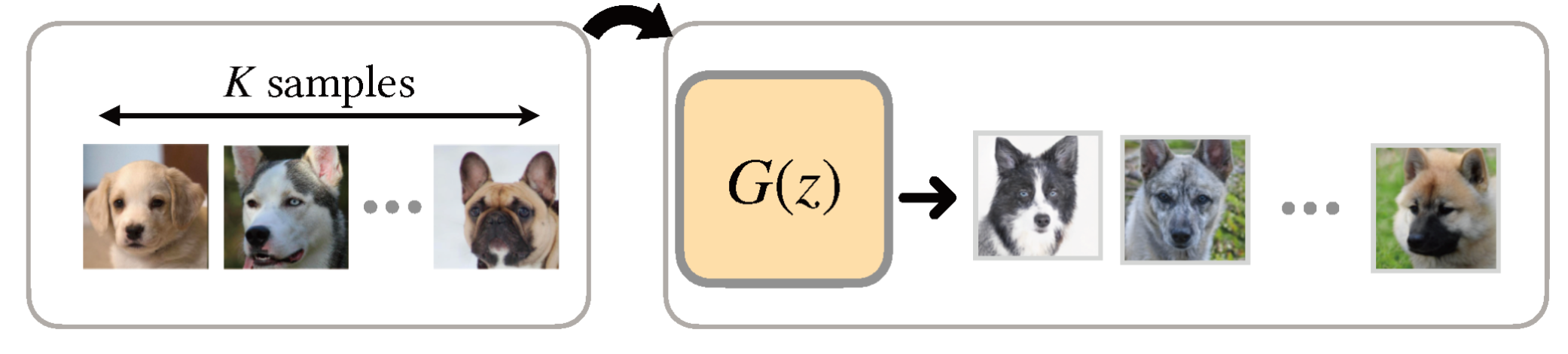
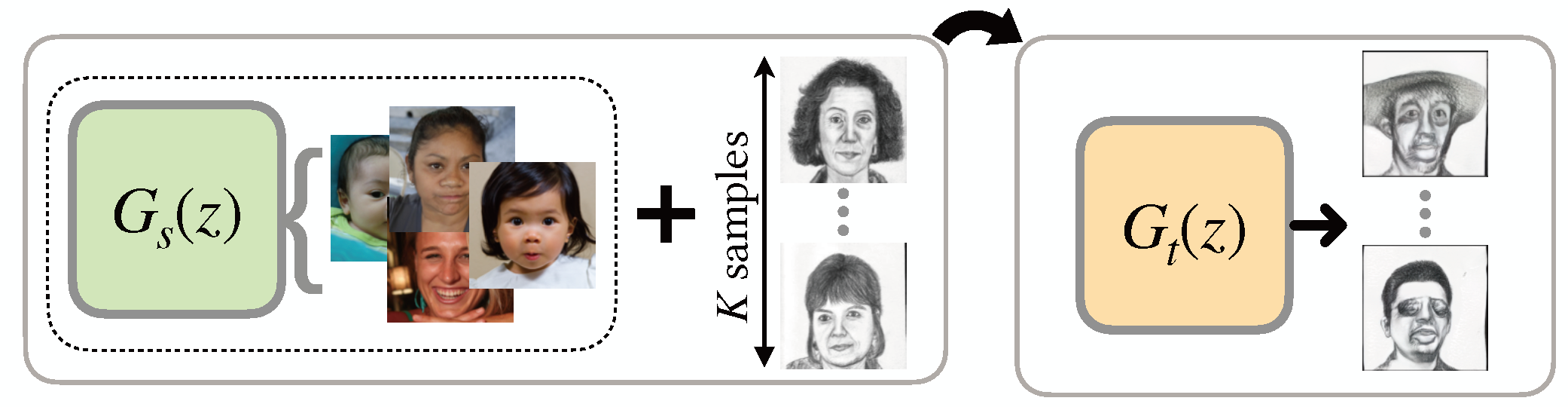
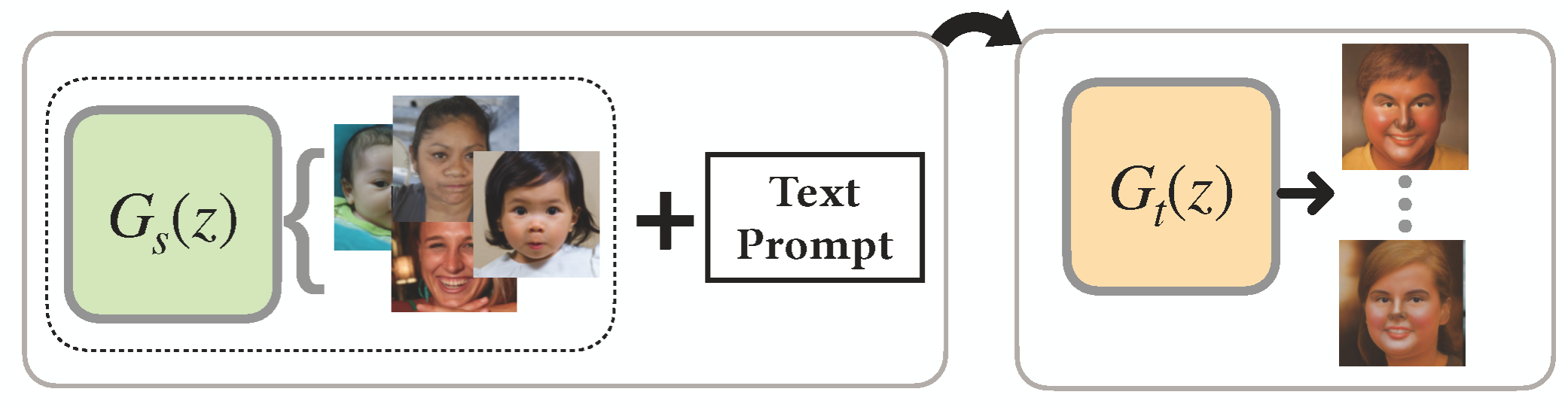
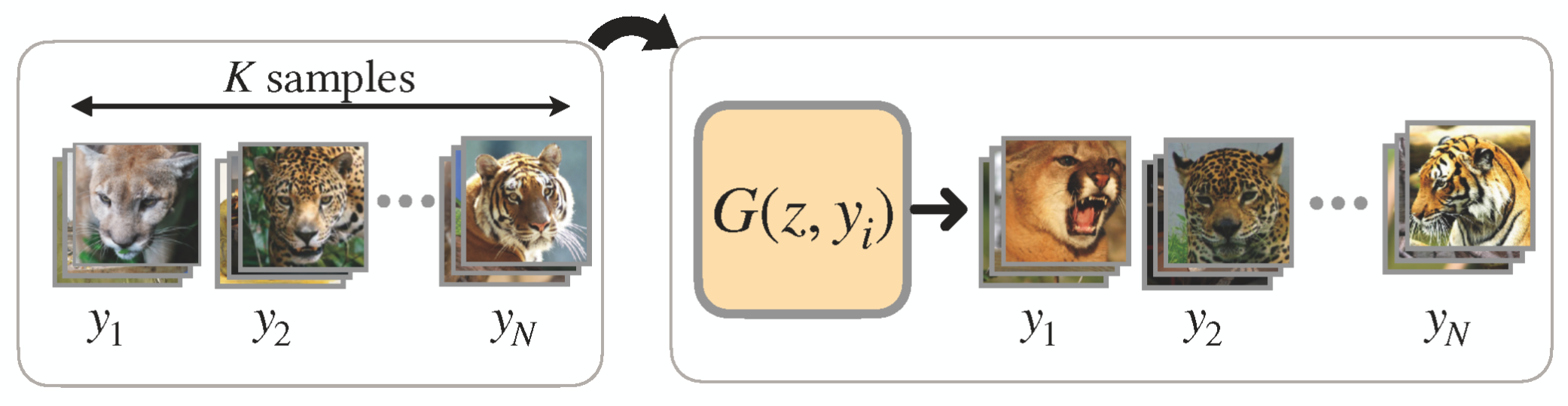
We propose 7 categories of approaches for GM-DC including Transfer Learning, Data Augmentaion,
Network Architectures, Multi-Task Objectives, Exploiting Frequency Components, Meta-Learning,
and Modeling Internal Patch Distribution. For more details on each category, and the
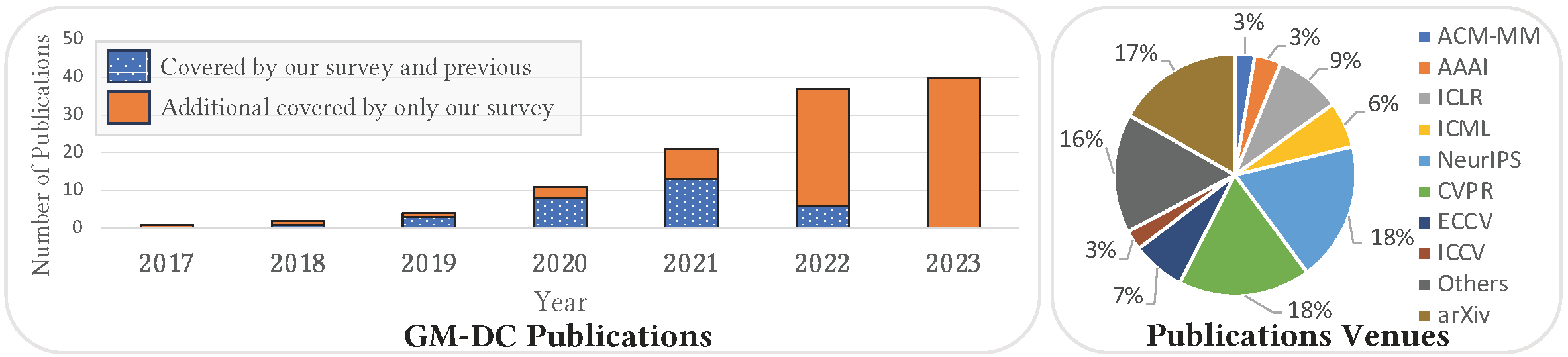
comprehensive review of these works, please check our paper. The list of papers including the
link and code for each paper, can also be found in our
GitHub Repository for GM-DC
.
Our proposed taxonomy for approaches in GM-DC. For each approach, the addressed GM-DC tasks
(see Tab. 2 for task definitions) and the data constraints are indicated.
A detailed list of methods under each sub-category is also tabulated (some methods are under multiple categories).
/ denotes the absence/presence of the tasks commonly addressed by each approach, and
the data constraints usually considered:
LD: Limited-Data, FS: Few-Shot and ZS: Zero-Shot.
|
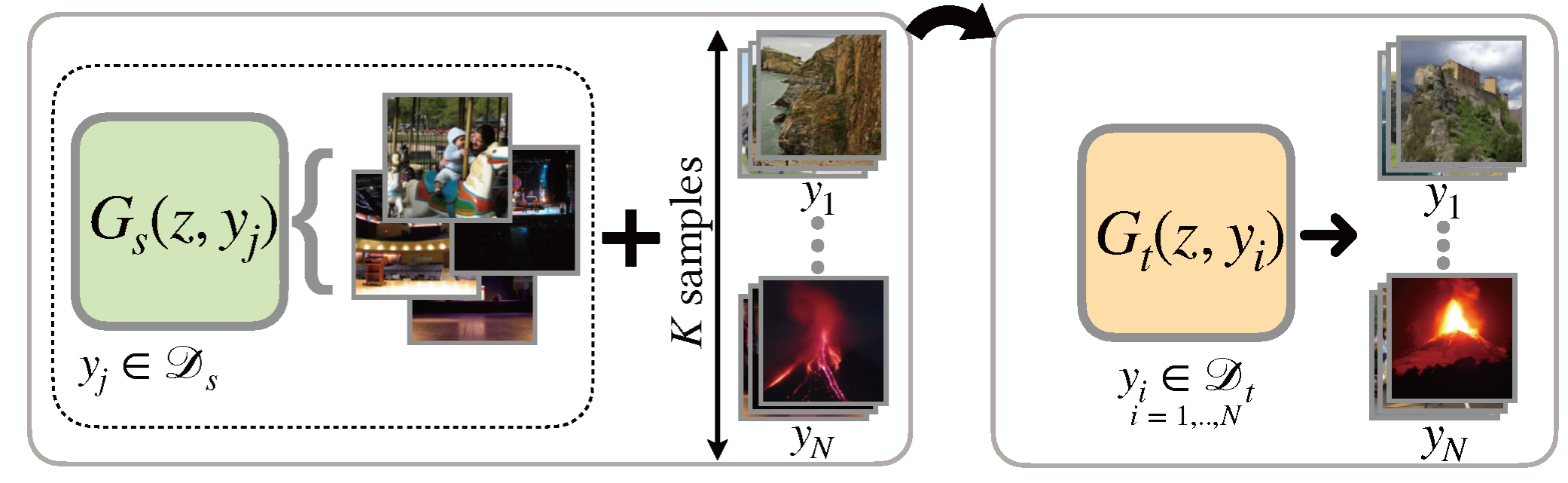
Transfer Learning (Sec. 4.1)
|
|
Description:
|
Improve GM-DC on target domain by knowledge of a generator pre-trained on source domain (with numerous and diverse samples).
|
|
Task:
|
uGM-1 uGM-2
uGM-3 cGM-1
cGM-2 cGM-3
IGM SGM
|
Data constraint:
|
LD
FS
ZS
|
1) Regularizer-based Fine-Tuning: Explore regularizers to preserve source generators' knowledge.
Methods: TGAN, BSA, FreezeD, EWC, CDC, cGANTransfer, W3, C3, DCL, RSSA, fairTL, GenOS\citep{zhang2022generalizedoneshot}
, SVD,
D3-TGAN, JoJoGAN,
KDFSIG, CtlGAN,
ICGAN,
MaskD,
F3,
ICGAN,
DDPM-PA,
DWSC,
CSR,
ProSC,
DOGAN,
AnyDoor,
SmoothSim,
TAN,
FPTGAN,
CLCR,
FastFaceGAN,
FDDC,
StyleDomain,
DomainExpansion,
CVD-GAN,
Def-DINO,
HDA,
FAGAN,
SSCR,
DPMs-ANT,
SACP,
DATID-3D
|
2) Latent Space: Explore latent space of source generator to identify suitable knowledge for adaptation.
Methods: MineGAN, MineGAN++,
GenDA,
TF2,
LCL,
SoLAD,
WeditGAN,
CRDI,
SiSTA, MultiDiffusion,
DiS
|
3) Modulation: Leverage trainable modulation weights on top of frozen weights of the source generator.
Methods: AdaFMGAN, GAN-Memory, CAM-GAN, AdAM, DynaGAN, HyperDomainNet, NICE, A3FT, LFS-GAN, OKM, CFTS-GAN, HyperGAN-CLIP, DPH, DoRM, Mix-of-Show, Orthogonal Adaptation, DreamMatcher, PortraitBooth, DisenDiff, RealCustom
|
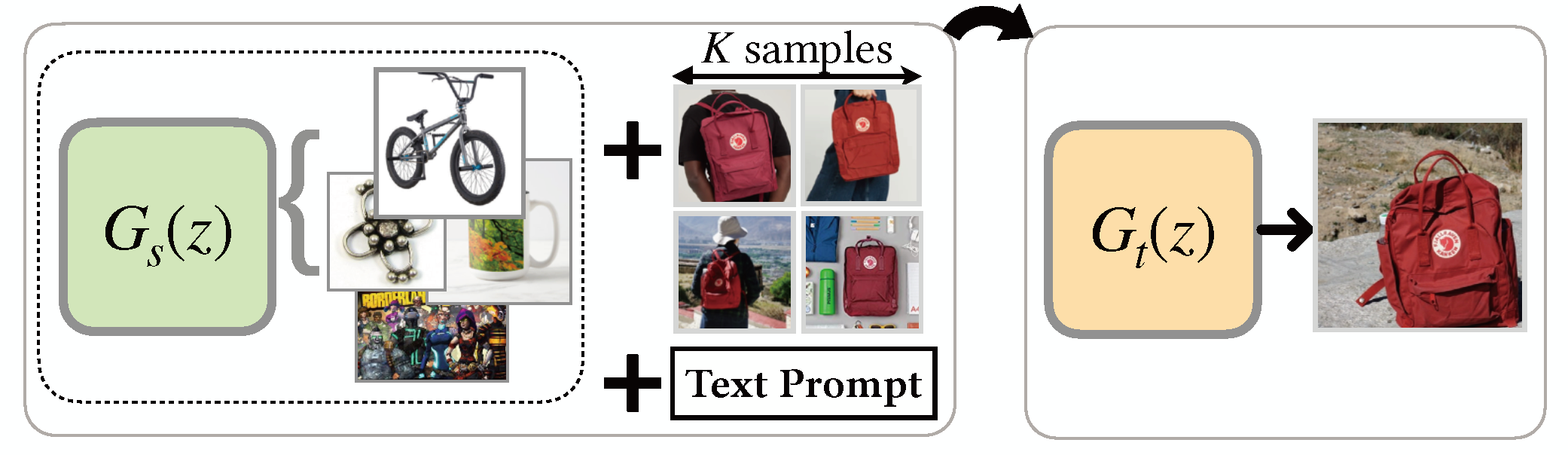
4) Natural Language-guided: Use the feedback of vision-language models to adapt the source generator with text prompts.
Methods: StyleGAN-NADA, MTG, HyperDomainNet, DiFa, OneCLIP, IPL, SVL, AIR, StyleGAN-Fusion, UniHDA,
\textsc{ITI-Gen},
FairQueue,
SINE, DreamBooth,
Custom Diffusion, Textual-Inversion, SpecialistDiffusion,
BLIP-Diffusion, AblateConcept, StyO, HyperGAN-CLIP, DPH, ELITE, E4T, MoMA, SSR-Encoder, MultiGen, MasterWeaver, Lego, CGR, DreamBlend, Cross Initialization, SAG, ZipLoRA, RealCustom, PALP, InstantBooth, IDAdapter, Domain gallery, LogoSticker, ProSpect, Dreambooth-CL, AnomalyDiffusion, ComFusion, SuDe, LFS-Diffusion, L2DM, Omg, TFIC, MagiCapture, Mix-of-Show, Orthogonal Adaptation, DBLoRA, HybirdBooth, T2IRL, HyperDreamBooth, FastComposer, PortraitBooth, DreamMatcher, DisenDiff, CII, DETEX
|
5) Adaptation-Aware: Preserve the source generator's knowledge that is important to the adaptation task.
Methods: AdAM, RICK, OKM
|
6) Prompt Tuning: Freeze the source generator and add/ generate visual prompts to guide generation for the target domain.
Methods: VPT
|
|
Data Augmentation (Sec. 4.2)
|
|
Description:
|
Improve GM-DC by increasing coverage of the data distribution by applying various transformations on the given samples.
|
|
Task:
|
uGM-1 uGM-2
uGM-3 cGM-1
cGM-2 cGM-3
IGM SGM
|
Data constraint:
|
LD
FS
ZS
|
1) Image-Level Augmentation: Apply data transformations on image space.
Methods: ADA, DiffAugment, IAG, DiffusionGAN, bCR, CR-GAN, APA, PatchDiffusion,
ANDA,
DANI,
AugSelf-GAN
|
2) Feature-Level Augmentation: Apply data transformations on the feature space.
Methods: AdvAug, AFI, FSMR
|
3) Transformation-Driven Design: Leverage the information of individual transformations to design an efficient learning mechanism.
Methods: DAG, SSGAN-LA
|
|
Network Architectures (Sec. 4.3)
|
|
Description:
|
Design specific architecture for the generator to improve its learning under data constraints.
|
|
Task:
|
uGM-1 uGM-2
uGM-3 cGM-1
cGM-2 cGM-3
IGM SGM
|
Data constraint:
|
LD
FS
ZS
|
1) Feature Enhancement: Design additional modules/ layers to enhance/retain the feature maps of the generator for better generative modeling.
Methods: FastGAN,
cF-GAN,
MoCA, DFSGAN,
DM-GAN,
FewConv,
SCHA-VAE
|
2) Ensemble Large Pre-trained Vision Models: Improve architecture by integrating pre-trained vision models to enable more accurate GM-DC.
Methods: ProjectedGAN,
SPGAN,
Vision-aided GAN,
P2D,
DISP
|
3) Dynamic Network Architecture: Improve generative learning with limited data by evolving the generator architecture during training.
Methods: CbC, PYP, DynamicD, AdvAug, Re-GAN, RG-GAN, AutoInfoGAN
|
|
Multi-Task Objectives (Sec. 4.4)
|
|
Description:
|
Introduce additional task(s) to extract generalizable representations that are useful for all tasks, to reduce overfitting under data constraints.
|
|
Task:
|
uGM-1 uGM-2
uGM-3 cGM-1
cGM-2 cGM-3
IGM SGM
|
Data constraint:
|
LD
FS
ZS
|
1) Regularizer: Add an additional task objective as a regularizer to prevent an undesirable behaviour during training generative model.
Methods: LeCam, DigGAN, MDL, RegLA
|
2) Contrastive Learning: Introduce a pretext task to enhance the learning process of the generative model.
Methods: InsGen, FakeCLR, DCL, C3, ctlGAN, IAG, CML-GAN, RCL
|
3) Masking: Mask a part of the image/ information to increase the task hardness and prevent learning the trivial solutions.
Methods: MaskedGAN, MaskD, DMD
|
4) Knowledge Distillation: Add a task objective that enforces the generator to follow a strong teache.
Methods: KD-DLGAN, KDFSIG, BK-SDM
|
5) Prototype Learning: Emphasize learning prototypes for samples/ concepts within the distribution as an additional task objective.
Methods: ProtoGAN, MoCA
|
6) Other Multi-Task Objectives: Apply other types of multi-task objectives including co-training, patch-level learning, and diffusion.
Methods: GenCo, PatchDiffusion, AnyRes-GAN , DiffusionGAN, D2C, AdaptiveIMLE, FSDM
|
|
Exploiting Frequency Components (Sec. 4.5)
|
|
Description:
|
Exploit frequency components to improve learning the generative model by reducing frequency bias.
|
|
Task:
|
uGM-1 uGM-2
uGM-3 cGM-1
cGM-2 cGM-3
IGM SGM
|
Data constraint:
|
LD
FS
ZS
|
|
Methods: FreGAN, WaveGAN, MaskedGAN, Gen-co, FAGAN, SDTM
|
|
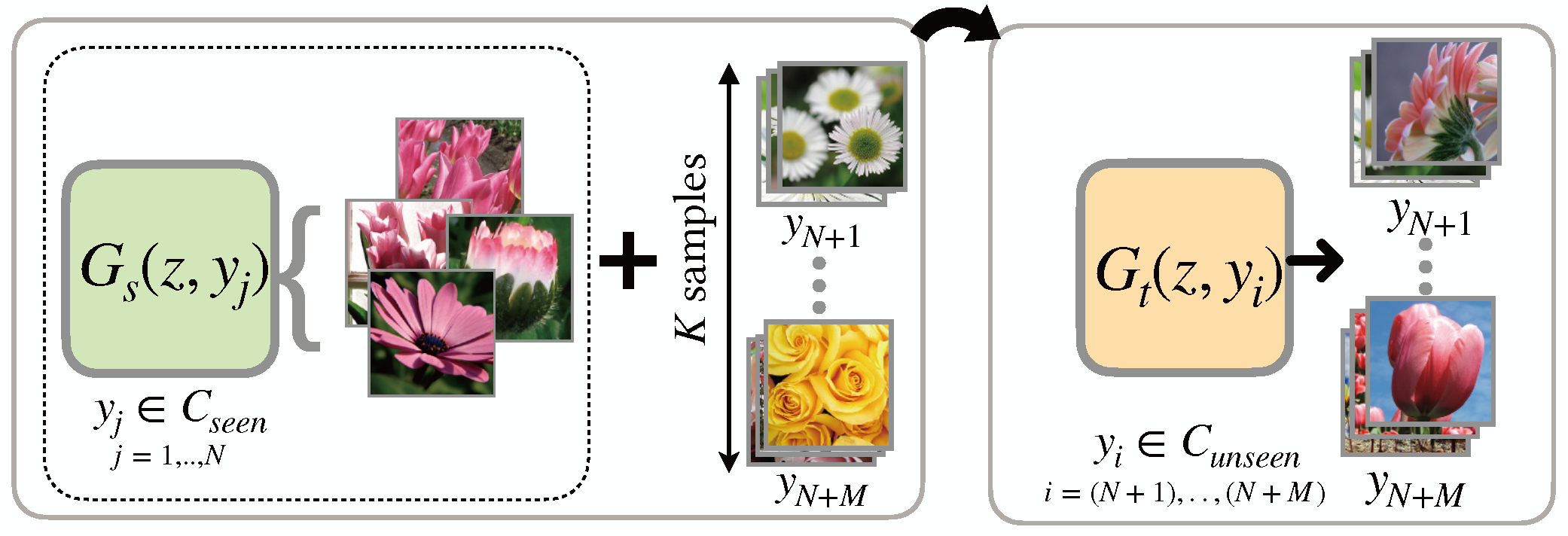
Meta-Learning (Sec. 4.6)
|
|
Description:
|
Learn meta-knowledge from seen classes to improve generator learning for unseen classes.
|
|
Task:
|
uGM-1 uGM-2
uGM-3 cGM-1
cGM-2 cGM-3
IGM SGM
|
Data constraint:
|
LD
FS
ZS
|
1) Optimization: Learn initialization weights from the seen classes as meta-knowledge to enable quick adaptation to unseen classes.
Methods: GMN, FIGR, Dawson, FAML, CML-GAN
|
2) Transformation: Learn sample transformations from the seen classes as meta-knowledge and use them for sample generation for unseen classes.
Methods: DAGAN, DeltaGAN, Disco, AGE, SAGE, HAE, LSO, TAGE, CDM, ISSA, MFH
|
3) Fusion: Learn to fuse the samples of the seen classes as meta-knowledge, and apply learned meta-knowledge to generation for unseen classes.
Methods: MatchingGAN, F2GAN, LofGAN, WaveGAN, AMMGAN, MVSA-GAN, EqGAN, SDTM, SMR-CSL, SAGAN, F2DGAN
|
|
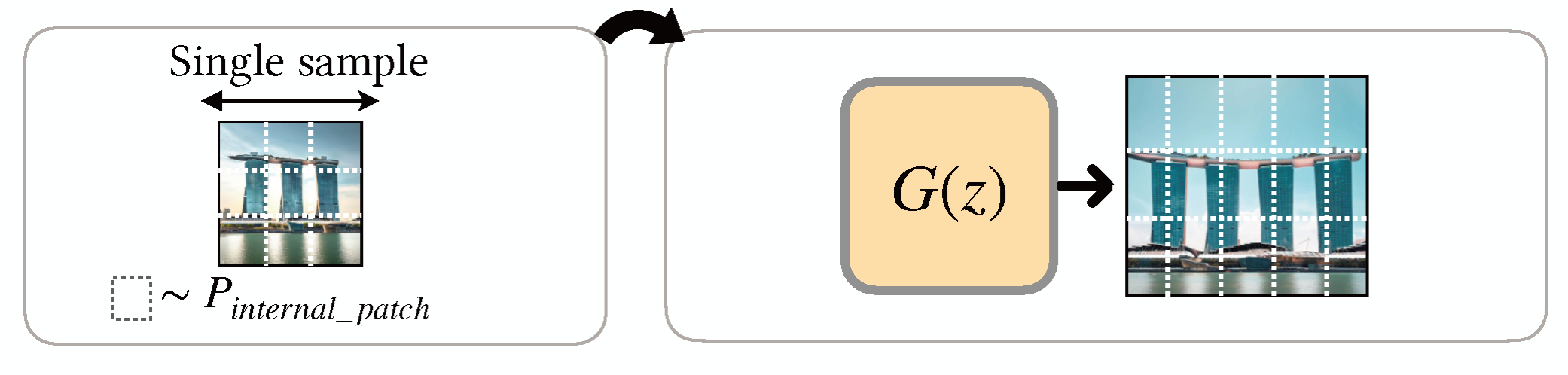
Modeling Internal Patch Distribution (Sec. 4.7)
|
|
Description:
|
Learn the internal patch distribution within one image to generate diverse samples with the same visual content (patch distribution).
|
|
Task:
|
uGM-1 uGM-2
uGM-3 cGM-1
cGM-2 cGM-3
IGM SGM
|
Data constraint:
|
LD
FS
ZS
|
1) Progressive Training: Train a generative model progressively to learn the patch distribution at different scales/ noise levels.
Methods: SinDiffusion, SinDDM, Deff-GAN, BlendGAN, SinGAN, ConSinGAN, CCASinGAN, PromptSDM, LatentSDM, SD-SGAN, SA-SinGAN, ExSinGAN, TcGAN, RecurrentSinGAN
|
2) Non-progressive Training: Train a generative model on the same scale/ noise but with changes to the model’s architecture.
Methods: SinFusion, One-Shot GAN, PetsGAN
|